Maintenance’s Role in Industrial System Longevity

TL;DR:
- Effective maintenance extends system lifespan by preventing faults through strategic inspections, lubrication, and repairs. Using frameworks like RCM and PHM, managers tailor maintenance to asset criticality and failure modes, optimizing reliability. Frequent strategy reassessment and integrating condition data ensure maintenance efforts remain aligned with evolving operational risks.
Maintenance is the primary mechanism that extends system longevity by detecting and correcting faults before they escalate into failures. The role of maintenance in system longevity spans three core disciplines: preventive maintenance, predictive maintenance, and corrective maintenance. Each targets a different stage of the failure curve. Frameworks like Reliability-Centered Maintenance (RCM) and Prognostics and Health Management (PHM) give facility managers and engineering professionals the structure to apply these disciplines where they produce the greatest return. Technologies including CMMS platforms, vibration sensors, and thermographic cameras support execution, but strategy always comes first.
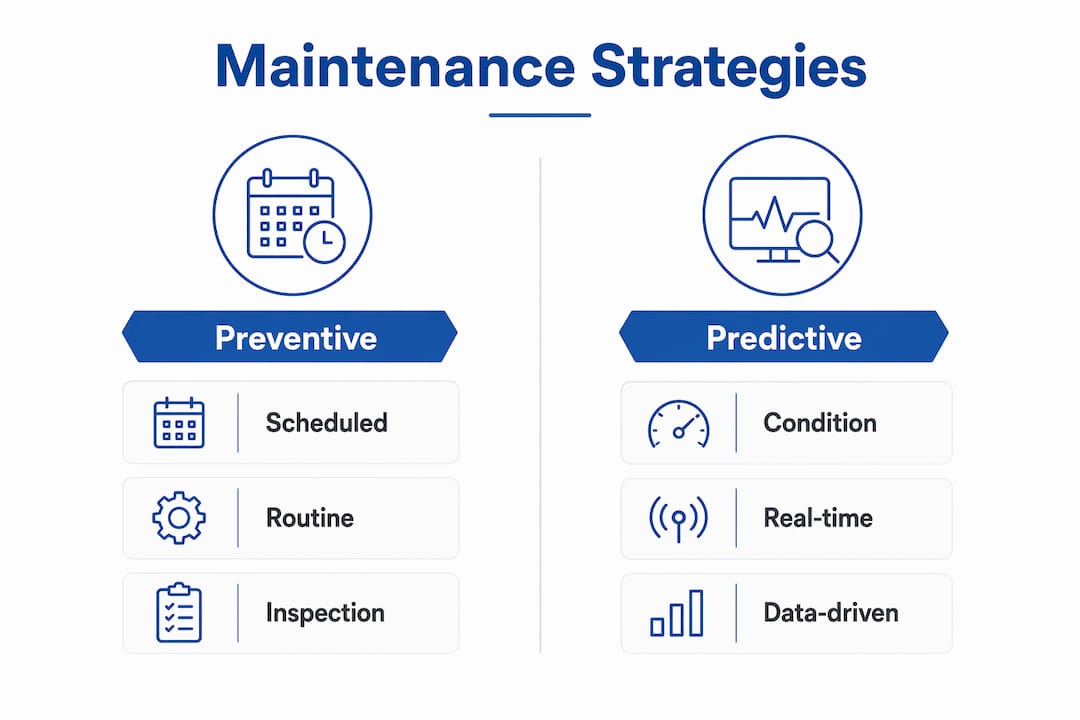
How does preventive vs. predictive maintenance extend asset life?
Preventive maintenance extends equipment life by stopping small faults from becoming failures through scheduled inspection, cleaning, lubrication, calibration, and part replacement. This approach is more cost-effective than run-to-failure strategies because it controls when work happens, not the failure event itself. Unplanned failures carry hidden costs: emergency labor rates, collateral equipment damage, and production losses that dwarf the cost of a scheduled service visit.

Predictive maintenance takes a different approach. Rather than servicing assets on a fixed calendar, it uses condition-monitoring data to determine the right moment to intervene. A 2026 Springer study on gearbox systems showed that predictive RUL estimation achieved failure prediction deviations below 1%, with RMSE values near 0.11 and MAE near 0.04 under dense sensor monitoring. That level of accuracy means maintenance teams can schedule interventions days or weeks before a failure, not hours after one.
The practical difference between these two strategies matters for resource allocation:
- Preventive maintenance works best for assets with predictable wear patterns, such as filters, belts, and bearings with known service intervals.
- Predictive maintenance works best for high-value assets where failure consequences are severe and condition data is available in real time.
- Corrective maintenance should be reserved for non-critical assets where run-to-failure carries no safety or production risk.
- Condition-based triggers replace arbitrary time intervals, reducing unnecessary disassembly and the risk of introducing new faults during service.
Pro Tip:Before investing in predictive monitoring hardware, map your assets by criticality. Predictive tools deliver the highest return on assets where a single failure causes production stoppage or safety risk. Apply preventive schedules everywhere else.
What are RCM and PHM, and how do they maximize system lifespan?
Reliability-Centered Maintenance and Prognostics and Health Management represent the two dominant strategic frameworks for extending system lifespan. They are not interchangeable. Understanding what each does, and where each applies, is the foundation of any serious maintenance strategy for longevity.
RCM: linking maintenance to failure consequences
RCM methodology, codified in SAE JA1011, uses a seven-question decision logic to connect every maintenance task to a specific asset function and its failure consequences. The process asks: What does the asset do? What constitutes a failure? What causes that failure? What happens when it fails? Does it matter? What can be done to prevent it? What if prevention is not feasible? This logic forces teams to justify every task on the maintenance schedule. Tasks that cannot be linked to a failure consequence get removed. That is how RCM eliminates over-maintenance, which is the practice of servicing assets more frequently than their failure modes require.
PHM: a lifecycle-wide approach
PHM is a closed-loop maintenance framework that integrates diagnostics, prognostics, and decision support across the full asset lifecycle. Where RCM defines what to maintain and why, PHM defines how to monitor, predict, and act on asset health data continuously. PHM aligns maintenance decisions with risk tolerance, resource constraints, and performance objectives simultaneously. The result is reduced lifecycle costs and lower operational downtime without sacrificing reliability or availability.
| Framework | Core Logic | Best Application | Primary Benefit |
|---|---|---|---|
| RCM | Failure-mode-based task selection | Asset criticality ranking and task justification | Eliminates unnecessary maintenance tasks |
| PHM | Diagnostics and prognostics integration | High-value assets with sensor infrastructure | Predicts failures before they occur |
| Preventive PM | Time-based intervals | Assets with predictable wear patterns | Controls when work happens |
| Corrective | Run-to-failure | Non-critical, low-consequence assets | Minimizes maintenance overhead |
Pro Tip:RCM and PHM work best together. Use RCM to decide which assets deserve intensive monitoring, then apply PHM tools to those assets. Applying PHM universally without RCM prioritization wastes sensor investment and analyst time.
Does high PM compliance actually guarantee reliability?
High preventive maintenance compliance does not guarantee asset reliability. This is one of the most counterintuitive and consequential findings in modern maintenance management. PM compliance metrics measure whether scheduled tasks were completed on time. They do not measure whether those tasks addressed the actual degradation mechanisms threatening the asset.
CMMS platforms like IBM Maximo, SAP PM, and Infor EAM are powerful tools for scheduling, tracking, and reporting maintenance activity. Their limitation is structural. A CMMS records that a task was done. It does not capture whether the asset experienced abnormal thermal loading last week, whether vibration signatures have been trending upward for three months, or whether a process change introduced a new stress the original PM plan never anticipated.
Real-world maintenance programs regularly show this gap:
- Assets with 95%+ PM compliance rates still fail unexpectedly because the PM tasks were not aligned to the actual failure modes driving degradation.
- Condition monitoring data sitting in a separate system from the CMMS creates blind spots that no compliance report can reveal.
- Operational telemetry, such as load profiles, temperature excursions, and cycle counts, often contains the earliest warning signals of impending failure.
- Asset Performance Management frameworks close this gap by fusing maintenance records with condition and operational data into a single health picture.
The practical implication is direct. Compliance metrics are a necessary input, not a sufficient output. Facility managers who report PM completion rates to leadership without pairing that data with condition trends are measuring activity, not reliability. The importance of system maintenance is only realized when the data from that maintenance is interpreted in context.
Maintenance best practices that actually extend system life
Effective maintenance programs for longevity share a common structure. They start with clear reliability objectives, execute targeted interventions, and reassess strategy as operating conditions change. Reliable Plant defines this as a living asset-management loop: define, execute, and review. Technology serves that loop. It does not replace it.
Practical best practices for facility managers include:
- Define what must not fail. Every facility has a short list of assets whose failure causes safety incidents, regulatory violations, or production losses. Start there. Build your most intensive maintenance coverage around those assets first.
- Replace uniform schedules with failure-mode-based plans. Applying the same PM interval to every pump, motor, or panel regardless of its operating context is a resource waste. RCM-driven task selection focuses effort on the failure drivers that actually threaten longevity.
- Integrate condition-based triggers. Vibration analysis, oil sampling, thermography, and ultrasonic testing each detect specific failure modes earlier than calendar-based inspections. Assign the right tool to the right failure mode.
- Schedule planned downtime during low-demand periods. Maintenance windows aligned with production valleys reduce the operational cost of taking assets offline and give technicians adequate time to do the work correctly.
- Invest in technician training and documentation accuracy. A well-designed maintenance strategy fails at the wrench. Technicians who understand why a task matters, not just how to complete it, catch anomalies that a checklist never captures. Accurate work-order documentation feeds the data loop that improves future decisions.
- Reassess strategy periodically. Operating contexts change. New equipment, process modifications, and regulatory updates all shift the failure risk profile of your assets. A maintenance strategy that was correct two years ago may be misaligned today.
Pro Tip:Set a formal strategy review on a 12-month cycle at minimum. Use it to compare your PM task list against the failure modes your team actually encountered during the year. Tasks that never prevented a real failure are candidates for removal or frequency reduction.
The lightning protection maintenance workflow published by Indelec illustrates this principle well. Inspection, calibration, and monitoring are sequenced around the specific failure modes of protection systems, not generic service intervals. That specificity is what makes the program effective.
Key takeaways
Maintenance extends system longevity only when strategy, execution, and data integration work together as a continuous loop, not as isolated tasks.
| Point | Details |
|---|---|
| Strategy precedes technology | Define reliability objectives and failure modes before selecting monitoring tools or CMMS platforms. |
| Predictive accuracy is proven | Studies show failure prediction deviations below 1%, making predictive maintenance viable for high-value assets. |
| PM compliance is not reliability | High task completion rates do not guarantee asset health without integration of condition and operational data. |
| RCM eliminates over-maintenance | Failure-mode-based task selection removes unnecessary work and focuses resources on real longevity drivers. |
| Strategy must evolve | Reassess maintenance plans annually as operating contexts, equipment, and organizational goals change. |
Indelec’s perspective on maintenance as a longevity discipline
After decades of working with industrial and infrastructure clients across demanding environments, one pattern stands out clearly. The facilities with the longest-lived systems are not the ones with the largest maintenance budgets. They are the ones with the clearest thinking about what failure actually costs them.
The most common mistake we see is treating maintenance as a task-completion exercise. Teams hit their PM compliance numbers, close their work orders, and report green dashboards, while the asset continues degrading along a failure mode the PM plan never addressed. That gap between activity and outcome is where system life gets cut short.
What actually works is the mindset that Reliable Plant describes: strategy first, technology second. We have seen facilities deploy expensive sensor networks and CMMS upgrades without first defining what failure they are trying to prevent. The data accumulates. Nobody acts on it. The asset fails anyway.
The facilities that get this right treat their maintenance program as a living document. They review it when processes change, when new equipment arrives, and when a failure surprises them. They ask why the failure happened and whether their strategy should have caught it. That discipline, more than any specific tool or technology, is what drives long-term system reliability.
— Indelec
How Indelec supports long-term system protection and reliability
Indelec has specialized in protecting industrial and infrastructure assets from electrical threats since 1955. The same principles that govern effective maintenance strategy, targeted intervention, condition-based monitoring, and lifecycle thinking, apply directly to lightning protection systems.
The Prevectron3 lightning rod with OptiMax technology is designed for facilities where protection system failure carries severe consequences. Indelec’s maintenance and inspection services work alongside facility managers to keep protection systems compliant, calibrated, and performing across their full service life. Whether you are managing a new installation or auditing an aging protection network, Indelec’s technical team brings the same failure-mode-based discipline to lightning protection that the best maintenance programs apply to every critical asset.
FAQ
What is the role of maintenance in system longevity?
Maintenance extends system longevity by preventing small faults from escalating into failures through scheduled inspection, lubrication, calibration, and part replacement. Proactive maintenance strategies consistently outperform run-to-failure approaches in both cost and asset lifespan.
How does predictive maintenance differ from preventive maintenance?
Preventive maintenance follows fixed time-based intervals, while predictive maintenance uses real-time condition data to trigger interventions only when asset health data indicates an approaching failure. Predictive approaches reduce unnecessary disassembly and can achieve failure prediction accuracy within 1% deviation.
Why does high PM compliance not guarantee reliability?
PM compliance measures whether scheduled tasks were completed, not whether those tasks addressed the actual degradation mechanisms threatening the asset. Facilities must integrate maintenance records with condition monitoring and operational data to get an accurate picture of true asset health.
What is reliability-centered maintenance (RCM)?
RCM is a structured methodology, codified in SAE JA1011, that links every maintenance task to a specific asset function and failure consequence using a seven-question decision logic. It eliminates over-maintenance by removing tasks that cannot be justified by a real failure mode.
How often should a maintenance strategy be reassessed?
Maintenance strategies should be formally reviewed at least once every 12 months, and immediately following any significant process change, equipment addition, or unexpected failure event. Operating contexts shift, and a strategy that was correct last year may no longer match the current failure risk profile.



